mysqldumpの結果を定期的にS3に保存する方法

目次
スポンサードリンク
mysqlで管理しているデータを、定期的にサーバー外にバックアップする方法を紹介します。 バックアップの保存先にAWSのS3に保存することにしました。S3ならコストも安く、過去数日間のファイルのみ残しておくなどライフサイクルの設定も簡単にできるので手軽にバックアップが取れておすすめです。
IAMユーザーの準備
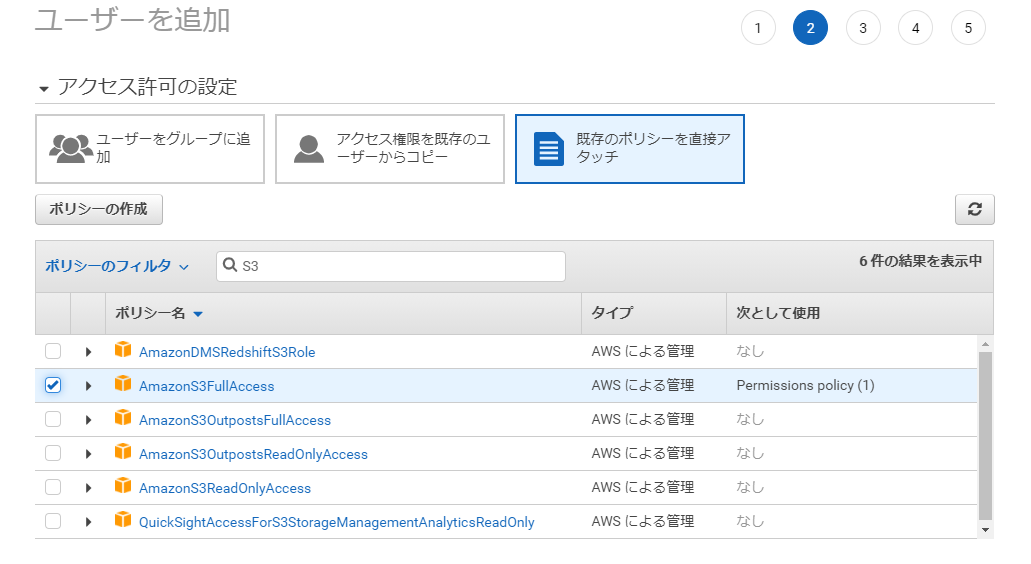
まずは、バックアップファイルをS3に保存する際に使用するユーザーを作成しておきます。 今回はAWS CLIを使ってファイルを転送するので「プログラムによるアクセス」を選択しておきます。

ポリシーのアタッチ
ポリシーはファイルアップロードができるようにAmazonS3FullAccessを選択しておきます。
シェルスクリプトの用意
mysqldumpコマンドでバックアップを取得し、取得したバックアップファイルをS3に転送する。
#!/bin/sh
BACKUP_FILENAME="dump_`date "+%Y%m%d_%H%M%S"`.sql"
mysqldump --defaults-extra-file=/root/bin/.my.db.cnf --single-transaction database_name --quick | /usr/local/bin/aws s3 cp - s3://backup/$BACKUP_FILENAME
logger "Saved the database dump file in s3 with the name $BACKUP_FILENAME."
exit 0
データベースの接続情報は別ファイルに記載しておく。
# cat /root/bin/.my.db.cnf
[client]
user=symm
password="データベースの接続パスワード"
host=127.0.0.1
cronの設定
起動はcronから。定期的にバックアップ処理を記載したシェルを実行する。
00 * * * * /root/bin/dump_.sh
シェルスクリプトでs3にファイル保存する際の注意点
シェルスプリプと内に記述するコマンドは、フルパスで記述する必要があります。 あるいは、crontab内でPATH環境変数を宣言しておけばいい。
PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin:/usr/local/bin
* * * * * cronjob
シェルスクリプトの知識は、プログラマにとって長く役立つ知識です。 私はこちらの書籍で一通り知識を抑えました。基本から丁寧に解説されています。
リンク
最短3時間で覚えるLinuxシェルスクリプト
こちらは、シェルスクリプトの基本的な書き方、デバッグ方法、if, case, while, forなど基本的な制御構文について書かれています。30日間の無料体験もできる『Kindle Unlimited』でも読むことができます。
リンク
